L’istituto persegue l’eccellenza nella ricerca scientifica e svolge un ruolo attivo nel trasferimento tecnologico. Il settore di competenza copre la Scienza dell’Informazione, le tecnologie correlate e una vasta gamma di applicazioni. L’attività è rivolta ad accrescere le conoscenze, sviluppare e sperimentare nuove idee e ad ampliare i campi di applicazione. L’Istituto svolge attività di ricerca, di trasferimento tecnologico e di formazione nelle principali aree tematiche delle Tecnologie dell’Informazione: Sistemi e Reti, Tecnologie del Software, Sistemi di Gestione dell’Informazione e della Conoscenza, Elaborazione Grafica e di Immagini, Applicazioni Computazionali. Ad ognuna delle aree tematiche afferiscono i laboratori dell’ISTI. L’ISTI è attivamente coinvolto in collaborazioni con le università e partecipa a consorzi di ricerca e a programmi di sviluppo, sia nazionali sia internazionali. L’Istituto attribuisce grande importanza anche all’attività di formazione, coinvolgendo gli allievi di dottorato e gli studenti di post-dottorato nelle attività di ricerca collaborando ai corsi di laurea dell’università di Pisa e di altre università.
L’Istituto di Linguistica Computazionale, fin dalle origini, ha svolto un ruolo centrale nel dibattito scientifico nazionale e internazionale sull’apporto dell’informatica agli studi umanistici. L’attività strategica svolta dall’ILC è basata sull’intuizione che la conservazione, lo spoglio e la fruizione dei testi del patrimonio culturale debbano coniugarsi con l’elaborazione della loro struttura linguistica e del loro contenuto attraverso l’uso di risorse e di strumenti di analisi linguistica automatica del testo. Le principali linee di ricerca e sviluppo nel settore delle Digital Humanities possono essere ricondotte ai seguenti filoni: acquisizione e conservazione di testi; progettazione e sviluppo di risorse e strumenti per il trattamento automatico di lingue classiche e varietà storiche della lingua; progettazione e sviluppo di strumenti per l’analisi del testo; costruzione di un’infrastruttura italiana per la ricerca nell’ambito delle scienze umane e sociali.
Le competenze dell’ILC si articolano in quattro macro-aeree tematiche:
-
analisi testuale, traduzioni, filologia collaborativa e cooperativa;
-
risorse e infrastrutture linguistiche;
-
trattamento automatico del linguaggio e gestione della conoscenza;
-
modelli bio-computazionali del linguaggio e della cognizione.
La ricerca all’interno di ciascuna area è altamente interdisciplinare e coinvolge competenze e professionalità principalmente condivise tra linguistica, linguistica computazionale, filologia e bio-ingegneria, da cui sono mutuate tecniche e metodologie.
Nel settore delle Digital Humanities, le priorità dell’ILC sono riconducibili ai seguenti punti:
-
convertire in formati standard le risorse digitali prodotte nel corso dei decenni presso l’Istituto, per garantirne la fruibilità e l’interoperabilità;
-
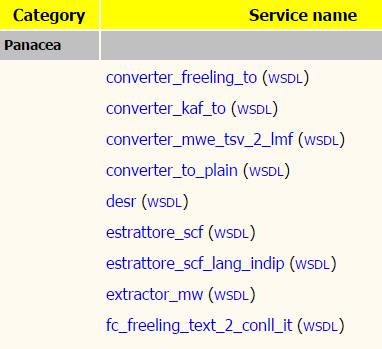
fornire sotto forma di servizi web le funzionalità del software legacy prodotto presso l’Istituto;
-
produrre la documentazione relativa a risorse, strumenti e servizi sviluppati nel tempo e messi a disposizione della comunità delle Digital Humanities;
-
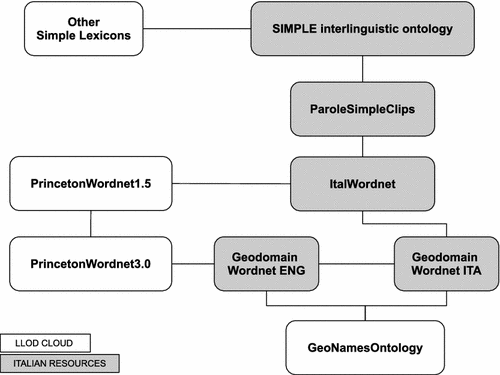
costruire ontologie per il dominio delle Digital Humanities;
-
costruire strumenti per l’analisi delle lingue classiche e per varietà storiche della lingua, l’estrazione di informazione da testi e il collegamento a thesauri e ontologie;
-
costruire strumenti di supporto alla consultazione, all’interpretazione, e alla traduzione di testi, in particolare testi letterari;
-
sviluppare procedure e ambienti per l’interazione e la gestione di testi, lessici e ontologie;
-
affrontare gli aspetti legati alle licenze aperte delle proprie risorse digitali e del proprio software.
A seguito della recente adesione dell’Italia come membro del CLARIN-ERIC, l’infrastruttura per le risorse e le tecnologie linguistiche dedicate alle scienze sociali e Digital Humanities, l’ILC è il centro nazionale di riferimento per il CNR ed ha il compito di definire il nodo CLARIN-IT, potenziarlo attraverso la costituzione ed il coinvolgimento di una rete nazionale di università, istituzioni di ricerca, biblioteche, musei che tipicamente posseggono e rendono disponibili collezioni di dati digitali e servizi linguistici. L’Istituto è inoltre partner del progetto infrastrutturale Parthenos, collabora con l’Open Philology Project dell’Università di Lipsia, partecipa allo scientific board dell’Associazione di Informatica Umanistica e Culture Digitali (AIUCD) e svolge attività di alta formazione nel settore dell’Informatica Umanistica attraverso la docenza di ricercatori all’interno di corsi presso università italiane e straniere e mediante il coinvolgimento di dottorandi, laureandi, stagisti e tirocinanti nelle attività di ricerca in corso.
Riferimenti: Simonetta Montemagni
Sito: http://www.ilc.cnr.it/
Discipline rilevanti: Art and Art History, Classical Studies, Communication Sciences, CH-Museology, Education, Geography, History, Linguistics, Literature